
Postgres Auto-Complete
In this article, you'll learn by example how to implement an auto-complete feature for your application using raw SQL and Postgres.
In this example, your application will display the list of distinct item names that come from some enormous item table. The application will have a drop-down input with two parts: an input box for searching and a list element displaying a subset of the available item names.
Here's an example you would like to achieve, as rendered in this, admittedly, cheaply mocked-up Google spreadsheet. Just imagine that the query that populated the drop-down really read a list of item names from a table containing hundreds of millions of rows.
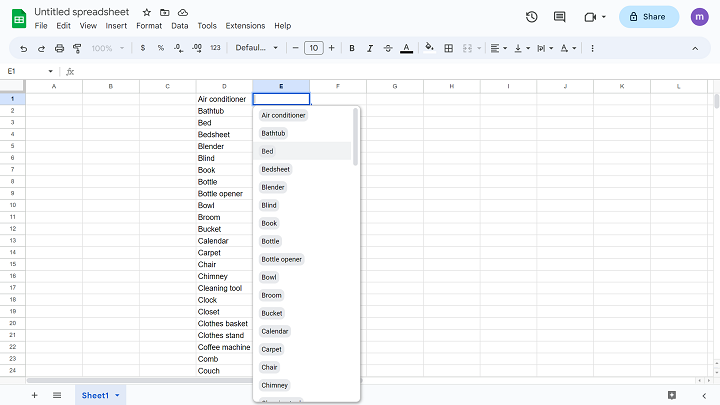
When the user begins to type some characters, the application waits for the input to settle using a debounce. Then a request is made to get the first results starting-with those characters.
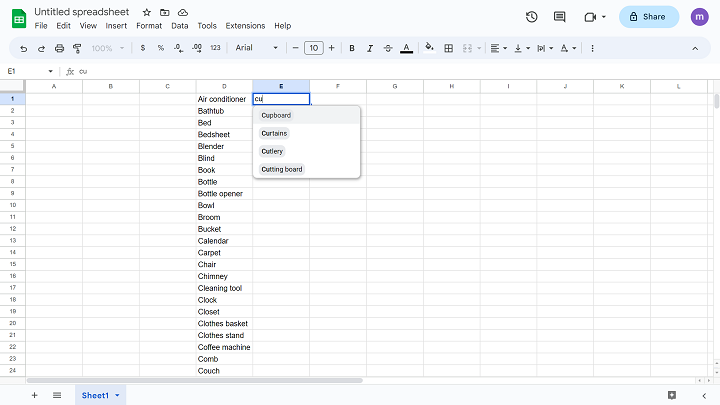
Ideally this query runs so fast the user barely waits for the possible responses to populate. The query has to return faster than even a couple hundred milliseconds. To achieve this type of speed and interaction with the Postgres database, you'll need to construct a very specific query.
Continue reading to understand more about reading distinct values in Postgres and by the end, you'll have a query you can use in your own applications to populate drop down lists and provide an auto-complete feature.
Understanding the Problem
The Postgres genetic query optimizer does not have index skip-logic capability. This means that the query optimizer cannot use an index to seek out distinct values - instead it will scan the entire index.
There are workarounds to the problem, as described in this article. The example query provided in the article provides the foundation for the auto-complete query.
The Workaround
Using the example query, begin with creating a query to retrieve the distinct item names.
Warning ⚠️ The query you’re about to see is not some run-of-the-mill SELECT statement! The important parts have been labeled e.g. [2] and are explained in further detail next.
-- [1] Recursive CTE WITH RECURSIVE distinct_values (distinct_value) AS ( ( -- [2] Seed query SELECT item_name FROM item_table WHERE ( item_name IS NOT NULL ) ORDER BY 1 LIMIT 1 ) -- [3] UNION ALL; required UNION ALL ( -- [4] Recursive query SELECT item_name FROM distinct_values, -- [5] Lateral join LATERAL ( SELECT item_name FROM item_table WHERE ( -- [6] Outer query value item_name > distinct_value ) -- [7] Forces index usage ORDER BY 1 -- [8] Extracts the next value LIMIT 1 ) X ) ) -- [9] Final select SELECT distinct_value FROM distinct_values -- [10] Arbitrary limit LIMIT 100
Note 🚧 You must build a btree index on the column you want to query.
This query has two major parts to it: the common table expression, or CTE [1-8], and the final SELECT clause [9-10], which reads that CTE.
The CTE component also introduces the keyword RECURSIVE [1]. This keyword allows the CTE to refer to itself in its own definition. Recursive CTE queries have a specific format: first starting with a seed query [2], then joined by UNION ALL [3], and finally ending with the recursive query [4-8].
In the recursive query above, since a sub-query is needed, the seldom used keyword LATERAL [5] is used. This type of join allows a sub-query to refer to the values provided in the outer query [6].
The sub-query is required because the ORDER BY and LIMIT clauses [7,8] are used to extract the next item name value greater than the last. The ORDER BY clause forces the optimizer to choose the btree index on that column.
Note 💡 If the ORDER BY and LIMIT clauses are used outside of the sub-query, then the recursion process would stop after returning only one row, resulting in at most two rows. This is also why it is necessary to wrap both the queries that make up the CTE in their own sets of parenthesis.
It is the final SELECT clause [9] that reads from the distinct values recursive CTE. When the query runs, the first item name is discovered and placed into the temporary table. This one row is the only seed row and its value is provided as input to the iterative process. Each subsequent iteration reads the next, single highest item name and places that value into the temporary table. This iteration stops at the arbitrarily specified LIMIT [10].
Note ✋ Since the query cannot complete until the recursion stops, it is important to understand that the results of this query must be finite. By its very one-value-at-a-time nature, this query should not be used to enumerate all the distinct item names across hundreds of millions of items. But, this query can extremely quickly and efficiently enumerate a small subset of the item names.
Adding Pagination
To provide pagination, the application provides the final value from the previous page of values as input to the next page. By adding a continuation handle, the query can resume with that value. This type of pagination is well-suited for use in an infinite scrolling interface.
Note 💡 The query engine will be able to pick up exactly where it left off using the btree index that is built on the column being queried. This will result in a much faster response time versus using OFFSET and LIMIT to paginate this type of query. If OFFSET and LIMIT were used instead, the engine would have to first discover the first OFFSET values only to then discard them upon reaching the desired page.
To add pagination, upgrade the seed query with additional WHERE criteria:
WITH RECURSIVE distinct_values (distinct_value) AS ( ( SELECT item_name FROM item_table WHERE ( item_name IS NOT NULL -- [1] Add continuation handle AND item_name > $1 ) ORDER BY 1 LIMIT 1 ) UNION ALL ( SELECT item_name FROM distinct_values, LATERAL ( SELECT item_name FROM item_table WHERE ( item_name > distinct_value ) ORDER BY 1 LIMIT 1 ) X ) ) SELECT distinct_value FROM distinct_values LIMIT 100
Now, the query will return all item names greater than the provided value [1].
Built-In Starts-With
Getting the first 100 distinct values using this specific query is great, but what happens when you try to add some form of starts-with?
There are several operators available in Postgres that can be used to filter rows where a column starts-with some arbitrary character data.
Here is a table describing starts-with operators you can find in Postgres.
| Operator | Example | Case-Sensitive ? |
|---|---|---|
| LIKE | item_name LIKE 'cu%' | Yes |
| ILIKE | item_name ILIKE 'cu%' | No |
| ~ | item_name ~ '^cu' | Yes |
| ~* | item_name ~* '^cu' | No |
| starts_with | starts_with(item_name, 'cu') | Yes |
| ^@ | item_name ^@ 'cu' | Yes |
While all these built-in operators will give some reasonable performance for smaller datasets, none of them will provide sub-second responses across all scenarios.
Most of the built-in operators do not scale well and will not be able to respond in a sub-second when multiple millions of rows are involved.
Some operators will return very quickly even against large datasets, provided there are a lot of matches. However, those same operators can in practice take multiple seconds, if not minutes to respond when there are very few or zero matches. This can be quite problematic for this type of interface as the goal to allow the user to quickly fumble through the available item names by trying different inputs.
Between ÿ
There is a special hack you can use when working with UTF-8 data that will provide impressively fast response times in the face of millions of rows, very few or very many hits, and it's case-insensitive to boot.
Instead of using one of the built-in operators for querying starts-with, use the BETWEEN operator. Here is an example of limiting the results to items whose names start with the characters 'cu'.
WHERE item_name BETWEEN 'cu' AND 'cuÿ'
Since the character input in the input box is UTF-8 character data, the largest single-character value is ÿ - ASCII point code 255. By filtering on item names between 'cu' and 'cuÿ', the query is taking advantage of UTF-8 collating sequence.
Consider the UTF-8 collating sequence: 'cup' is between 'cu' and 'cuÿ' because 'cup' is greater than or equal to 'cu' and the 'p' is less than or equal to the 'ÿ' in 'cuÿ' . In fact, all single-character values in the UTF-8 collating sequence are less than or equal to ÿ .
This is great because the BETWEEN operator is inclusive, which means that when a value is exactly equal to a boundary value, it is included in the output.
Putting it All Together
Here is the entire auto-complete query.
WITH RECURSIVE distinct_values (distinct_value) AS ( ( SELECT item_name FROM item_table WHERE ( item_name IS NOT NULL AND item_name > $1 -- [1] Add starts-with AND item_name BETWEEN $2 AND $3 ) ORDER BY 1 LIMIT 1 ) UNION ALL ( SELECT item_name FROM distinct_values, LATERAL ( SELECT item_name FROM item_table WHERE ( item_name > distinct_value -- [2] Add starts-with here too AND item_name BETWEEN $2 AND $3 ) ORDER BY 1 LIMIT 1 ) X ) ) SELECT distinct_value FROM distinct_values LIMIT 100
By adding the magical BETWEEN clause [1,2], the query will now:
- Return the first N, non-null distinct values;
- Utilize an optional infinite scrolling continuation handle;
- Filter item names with an optional starts-with value.
Note 🪄 Not only is this query really, really fast even against large datasets, it is also case-insensitive. What's more, the query will also surprisingly return relevant matches even when the user omits spaces or special characters found in the data.
Try It Out
If you have access to a Postgres database, here’s a script you can try out yourself to see how quickly this query really runs.
The script will:
- Execute a CREATE TABLE statement to receive data;
- Execute an INSERT statement having a generate_series function to generate random text;
- Execute a CREATE INDEX statement on the textual data as needed by the query;
- Execute a SELECT statement with the query to find distinct values starting with a random value.
CREATE TABLE public.item_table ( id BIGINT NOT NULL PRIMARY KEY, item_name TEXT NOT NULL ); INSERT INTO public.item_table SELECT ordinality, SUBSTRING( ENCODE( CONVERT_TO( RANDOM()::TEXT, 'utf8' ), 'base64' ) FROM (RANDOM() * 5)::INT FOR (RANDOM() * 20 + 3)::INT ) FROM GENERATE_SERIES(1,10000) WITH ORDINALITY; CREATE INDEX ON public.item_table USING BTREE (item_name); WITH RECURSIVE distinct_values (distinct_value) AS ( ( SELECT item_name FROM public.item_table WHERE ( item_name IS NOT NULL AND item_name BETWEEN '4nd' AND '4ndÿ' ) ORDER BY 1 LIMIT 1 ) UNION ALL ( SELECT item_name FROM distinct_values, LATERAL ( SELECT item_name FROM public.item_table WHERE ( item_name > distinct_value AND item_name BETWEEN '4nd' AND '4ndÿ' ) ORDER BY 1 LIMIT 1 ) X ) ) SELECT distinct_value FROM distinct_values LIMIT 100;
Update the range on the generate_series function to a large number, say 500,000,000 and see for yourself how fast this query runs against large datasets.
Related Posts
So you wanna learn some AWS skills huh?

SQL in io-ts, Part Two: Discriminating Unions & Expressions
Infrastructure as Code in TypeScript, Python, Go, C#, Java, or YAML with Pulumi
 Jack Ross
Jack Ross