
Introduction
GraphQL is a fantastic technology for aggregating numerous data sources into a single API and giving consumers incredible control over the data they wish to fetch…
…but what happens when you have UI tests running which hit your GraphQL server and subsequently fail because of issues in upstream systems?
When our tests fail, and it’s not our fault
Sometimes, tests will fail because the external data sources they are connected to may suffer from one or more of the following:
- The data is not controlled and is subject to change by other business users outside of any testing flow.
- The non-production environments are more volatile than their production counterparts, occasionally being unavailable or unable to handle the same volumes of calls.
- The non-production environments have bugs introduced as part of their own development & testing lifecycle.
Writing UI tests against any system which has unreliable backend dependencies can lead to flaky tests and false failures, and if these tests form a part of your CI process they can cost large amounts of time and money to investigate, fix and maintain.
Some examples, based on an e-commerce site:
- You have a UI test which verifies that a product on sale displays the appropriate “Sale” badge in the UI. If the product under test were to be changed to no longer be on sale, this test would fail, even though the UI logic is likely still sound.
- You have a test which verifies the shipping details displayed, where these details are fetched via your backend from a 3rd party system. If this system is unavailable for whatever reason, your test would fail, even though there wasn’t actually a fault in your code.
- You want to write a test to verify that the UI displays correctly for a product that is out of stock, but you have no way of knowing which product is out of stock at any given time; in this case, you cannot really write this test.
Addressing these issues is often a case of first trying to determine the point of failure, and if the point of failure is a system outside of your control, then you have three options:
- Remove the test entirely, since you cannot guarantee the presence or location of data to support it.
- Change the items under test to one that matches the test expectations. For example, if testing a product which was on sale, but is no longer on sale, then find another appropriate product and use that in the test.
- Perform some kind of pre-flight check to verify item or system availability prior to running the test, and use those dynamically identified items in your tests.
The third option involves significantly more effort and introduces randomness into tests due to data and system availability that cannot be predicted.
What options do we have?
Perhaps the best solution to this problem could be to set up a controlled test environment for the backend systems which give us full control of the data, allowing it to be immutable and predictable.
However, that option is not always available depending on the backend systems in use, and may not solve for the case of unavailability of the system or its own upstream dependencies. Therefore, we need to look for a way to remove the uncertainty and unpredictability of external systems from our test approach.
This is not a new problem. These challenges of writing tests in the context of external dependencies have been solved by utilising mocks: fake data which simulates the responses that these external systems would serve.
In the context of REST, we have libraries like nock, stubby and many more which can be used to intercept nominated requests and serve fake data in place of making the actual request to the intended recipient. This gives the test authors the ability to craft all kinds of test scenarios that assert the correct behaviours from their UIs given the types of responses it expects to receive.
These mocking libraries could also be used for GraphQL, although there is one important consideration: GraphQL has only one endpoint.
This limits your flexibility over how you structure your mock endpoints since these libraries are built around using the request URL as the discriminator for the mock.
For GraphQL, we need to look into the body of the request in order to establish what the request actually is. Let's look at the structure of a GraphQL request:
curl --request POST https://server.com/graphql \ --header 'Content-Type: application/json' \ --data-raw '{ "query": "query MyQuery($foo: String!) { myQuery(foo: $foo) { myData } }", "variables": { "foo": "bar" } }'
All requests to the GraphQL server will be POST requests to that https://server.com/graphql endpoint. The part which indicates the actual data being requested is in the request body, prettified below:
{ query: ` query MyQuery($foo: String!) { myQuery(foo: $foo) { myData } } `, variables: { foo: 'bar' } }
This tells us a number of things about this request:
- It is a
queryoperation (as opposed to amutationoperation). - The operation name is
MyQuery. - The operation expects a
foostring argument. - The query name (and root resolver in the GraphQL application) is
myQuery. - The request passes the value
'bar'for thefooargument.
With the above, there is enough information to be able to determine the intended GraphQL resolver for this query and to direct this request to a mock which would respond with some predictable data.
It’s entirely possible to write all of this logic yourself based on a single endpoint being intercepted by parsing the data in the request and routing to the appropriate mock data - but the complexity increases the more you try to match the behaviours of GraphQL. Some complexities worth calling out are:
- GraphQL only returns the fields of data which you specify - if you had two different calls to the same query which described different fields to return, your mock would need to return only the fields requested to be a perfect simulation.
- GraphQL supports features like fragments and directives which help define the fields that you are interested in, and you’d need to interpret and handle these in the expected way.
Is there a library available for this?
Yes. Thankfully some kind folks on the internet have graced us with a library that handles much of this for us: Mock Service Worker.
Mock Service Worker (msw) is not exclusively a GraphQL mocking library - you can mock REST endpoints with it as well - but it does have native support for mocking GraphQL operations.
It is also not exclusively a Service Worker library despite its name, since it only uses Service Workers to intercept requests coming from the client. For requests coming from the server (e.g., as part of a Server Side Render), it patches the various request modules such as node’s http and https modules to intercept and handle requests.
Using Mock Service Worker to mock your GraphQL backend
Installation
You first need to install msw and initialise it:
$ yarn add --dev msw # other package managers are available
You would then generate the service worker script by running:
# the <public_path> is the path in your application where your public assets # are stored. In NextJS and Create React App, this is typically ./public $ yarn msw init <public_path>
Then, you would write some code to register the client-side and server-side request interceptors and place this in your client application somewhere it will run before your app is started or mounted:
if (typeof window === 'undefined') { // running in node const { setupServer } = require('msw/node'); const server = setupServer(...handlers); server.listen(); } else { // running in browser const { setupWorker } = require('msw'); const worker = setupWorker(...handlers); worker.start(); }
This will start the appropriate listener based on whether the execution context is node or the browser.
So, what are those ...handlers? Those are what tell msw which REST and/or GraphQL requests we want to intercept and respond to with mock data.
Mocking a GraphQL query
Let's start with a simple query like this:
query Products { products { id name status } }
If we wanted to build UI tests over a variety of types of products, we would just need to ensure that the response for the above query contains data pertaining to every permutation of product data we wish to test.
For example:
{ "products": [ { "id": 1, "name": "👕 Blue shirt", "status": "IN_STOCK" }, { "id": 2, "name": "👟 Gray sneakers", "status": "ON_SALE" }, { "id": 3, "name": "🩳 Orange shorts", "status": "SOLD_OUT" }, { "id": 4, "name": "🧦 Brown socks", "status": "BACK_SOON" }, ] }
So how does msw allow you to handle requests for this GraphQL operation? Remember those ...handlers in the initialisation code above, they are going to come from a central registration of mock handlers, where we can use some of the utility functions provided by msw to mock specific operations.
import { graphql } from 'msw'; const handlers = [ // 👇 - name of the GQL operation graphql.query('Products', (req, res, ctx) => { // `res` comes from the arguments in the handler callback return res( // `ctx` also comes from the callback arguments, and `ctx.data` // ensures that the value is sent back in the `data` of the response ctx.data({ // JSON data to return products: [ { id: 1, name: '👕 Blue shirt', status: 'IN_STOCK' }, { id: 2, name: '👟 Gray sneakers', status: 'ON_SALE' }, { id: 3, name: '🩳 Orange shorts', status: 'SOLD_OUT' }, { id: 4, name: '🧦 Brown socks', status: 'BACK_SOON' }, ] }) ); }), // ... other handlers ];
The way that msw works is that it directs the requests to a mock which matches the operation name. That's an important caveat - msw mocks based on operation name rather than on the name of the query or mutation. For example, we could make two different queries:
query Products { products { id name price status } } query ProductImages { products { # 👈 note that this uses the same query as the one above id images { url description } } }
Both of these queries will use the products root query resolver, but as far as msw is concerned, they are different operations needing their own mock registrations - Products and ProductImages.
There is nothing stopping you from my pointing both of these registrations to the same code or even extracting functions to generate product data which can be utilised in both of these mocks and more. In fact, that's the recommended pattern.
Another nuance with these two queries is that they specify different fields to return. You could use the fact that these are separate mock handlers to control which data is returned in your mocks - i.e., have the Products one return just id, name, price and status data and the ProductImages one return just id, and url and description data of the images collection, but this again doesn’t scale particularly well, especially when we start to overlap the fields. There is a better way to handle returning only the requested fields, which we'll look at later.
Mocking a GraphQL mutation
Mocking a mutation is very similar to mocking a query, the only difference is the utility function used - graphql.mutation rather than graphql.query:
import { graphql } from 'msw'; const handlers = [ // 👇 - `graphql.mutation` vs. `graphql.query` graphql.mutation('Login', (req, res, ctx) => { return res( ctx.data({ authToken: 'foo' }) ); }) ];
GQL mutations generally involve some kind of side effect - either changing persisted data or calling on other systems to make a change of some kind. For the purpose of mocks, it may not be necessary to do this, since you don’t really care about the effects that the real mutation would have on external systems and you only want to return a mocked response which reflects the kind of data that would be returned.
However, in applications which rely on mutations to impact the user flow, you might need to consider simulating these mutations so that the experience better matches the real system, and this is where you can consider having your mocks persist some kind of state which can be referenced in subsequent GraphQL request mocks. We’ll cover this in a little more detail in a later section.
Handling query variables
Lets try something which needs to be a little more dynamic:
query Cart($id: ID!) { cart(id: $id) { items { productId, quantity } } }
This is a good example of an operation which likely would not have a single correct mock response. The contents of the cart could vary based upon the scenario being tested. For example, if we had a test which lets us add a 👕 Blue shirt to our cart, then it would make sense that the Cart operation would return a mock response indicating that the cart reflects having a 👕 Blue shirt product in the items array.
However, another test might want to assert what the UI displays for an empty cart, and so this Cart operation would be expected to return an empty items array.
How do we handle this? One way could be through smart use of the id variable for the query. If we can make it so that we control the id being sent to the query within our tests, we can return a different result based on that id.
For example, perhaps the test which wants to verify an empty cart ensures that the cart id is empty-cart, whereas the test for the UI after adding the "Red t-shirt" to our cart ensure that the cart id is cart-with-1-item.
We can use the incoming variables to inform the mock response:
import { graphql } from 'msw'; const handlers = [ graphql.query('Cart', (req, res, ctx) => { // for tests which want to verify an empty cart, // we use the id "empty-cart" if (req.variables.id === 'empty-cart') { return res( ctx.data({ cart: { items: [] } }) ); } // for tests which want to verify a specific product in the cart, // we use the id "cart-with-1-item" if (req.variables.id === 'cart-with-1-item') { return res( ctx.data({ cart: { items: [ { id: '53eb9bdc-3edd-4268-9e53-852cf0e1e30c', productId: '1', // 👕 Blue shirt quantity: 1, }, ], } }) ); } // not one of the above, it must be an invalid cart return res(ctx.errors([new GraphQLError('unknown cart')])); }), ];
This is a perfectly valid approach to handling varying responses, although as you can see from the above it will get much harder to manage at scale.
Another approach is to introduce a form of state management to your mocks, such that mutation operations such as AddToCart can stash some details in memory or in a state server, and subsequent Cart queries can retrieve those details and give a valid response.
Mocking error responses
Sometimes, you want to simulate sad-paths for your tests to verify that the application handles errors in the expected way.
GraphQL represents errors as an errors property in its response. Note that the overall response for errors from GraphQL is still an HTTP 200 response rather than any other HTTP status code. You can embed status codes or error codes as part of the error response data.
In msw we have a way to return an error response by using ctx.error(...) rather than ctx.data(...) in our response:
import { graphql } from 'msw'; import { GraphQLError } from 'graphql'; const handlers = [ graphql.mutation('Whoopsie', (req, res, ctx) => { return res( // 👇 `ctx.errors` vs. `ctx.data` ctx.errors([ new GraphQLError('Something went wrong') ]) ); }) ];
What if you don’t want to mock all of your GraphQL requests at once?
You may not want to write and introduce mocks for all of your operation at once. Perhaps you have too many GQL operations to mock, and the “big-bang” approach would involve too much time and effort to get buy in, or maybe there are just some GQL operations which you are not interested in writing mocks for at all.
Thankfully msw supports the ability to automatically fall-through to the real GraphQL application for any operations which you haven’t registered as a handler.
This means that you can focus on implementing mock handlers for the operations you are interested in, knowing that operations you haven’t yet mocked will continue to work as they did before.
Handling some GraphQL-specific behaviours
Your GQL mocks could start and end with some static responses to specific named operations if that is enough to satisfy your testing requirements. However, as your application grows, so do your test suites, and managing all of the required permutations of mocked responses as static data blobs becomes less and less viable.
At this point, you’ll want to consider some techniques which will make your GraphQL mock handlers better simulate the behaviours of a real GraphQL server.
Ensure that you only return the fields which were requested
One of the unique features of GraphQL is that the consumer has the ability to control what data they want to fetch and bring over the wire. If we have a catalog of products in our backend systems, then these products might have a lot of fields for their id, name, description, price, reviews, images, etc. In REST-based systems, you would need to be able to return all of the data for each product to the consumer so that they can use what they need, or you would need to craft separate endpoints or use properties of the request to provide some level of control as to what data is fetched.
A GraphQL server may know about all of the data (or more accurately, how to obtain all of the data), but the actual data sent over the wire is limited to the fields that are requested in the query.
This is something that we need to be mindful of in our mock system, since this functionality is not included automatically. For example, if we had the following mock handler for Products:
import { graphql } from 'msw'; const handlers = [ graphql.query('Products', (req, res, ctx) => { return res( ctx.data({ products: [ { id: 1, name: '👕 Blue shirt', description: '...snip: 4 paragraph description', status: 'IN_STOCK', price: 45.00, salePrice: null, material: 'Cotton', color: 'Blue', colorCode: '02', images: [ // ...snip: 10 image objects ], // ...snip: many other data points for a product }, // ... snip: hundreds of other products ] }) ); }), // ... other handlers ];
Maybe we write a query for this like follows:
query Products { products { id name price color } }
In this case, we only expect to get back the products with the id, name, price & color fields, and not the others. Therefore, if our handler always returns all of the data points for every product, whilst this would technically still work, it would have two problems:
- We are over-fetching the data, which may be a consideration if this results fetching large volumes of data which we don’t actually need or use and which impact the performance of the application under test.
- We could potentially have false positives in our testing. If we are using a data point in our UI which we are not asking for in our query, then the UI should fail to display that data in the real system, but in the mock system this failure would not show since we are returning all data including the data point we never asked for.
What we want to do is to honour the fields asked for in the query when responding.
This isn’t actually something that msw will do for you automatically, but thankfully it is not that difficult to do. The maintainers of msw recommend using the node GraphQL module to run the response through an executor against the schema and the query:
import { graphql } from 'msw'; import { buildSchema, graphql as gqlExecutor } from 'graphql'; import { schema } from 'schema.graphql'; const handlers = [ graphql.query('Products', (req, res, ctx) => { const fullData = { products: [/* ...snip: full product data from above... */] }; const { query } = await req.json(); const executionResult = await gqlExecutor({ // 👇 - this is the raw GQL schema as a string schema: buildSchema(schema), source: query, rootValue: fullData, variableValues: req.variables, }); return res( ctx.data(executionResult.data) ); }), // ... other handlers ];
This ensures that the response is filtered to only include the fields requested in the query. In addition, it factors in any fragments and directives in your query, which would otherwise have to be manually accounted for.
Ensure that the data in responses make sense in context
As your application grows, its reliance on data becomes more complex and dependent on prior operations which give context to the data you are requesting.
Going back to our previous Cart example, if we have a test scenario which involves adding a product to the cart and then verifying the cart page UI, we want to ensure that the cart page reflects the item that was added to our cart, rather than always reflecting a static mock cart response.
This means that our mutation to add an item to the cart - AddToCart - needs to set some state which can be obtained by the query which fetches the current cart - Cart.
How you choose to achieve this state persistence can vary based on your requirements and your infrastructure considerations. You could:
- Persist the data in memory in global variables.
- Persist the data in a state store.
When considering the in-memory approach, if your application under test operates with both Server Side Rendering (SSR) and Client Side Rendering (CSR), then each of these processes will use their own memory which is not shared, meaning that a GQL mutation in SSR followed by a GQL query in CSR would not have access to the same state. Therefore, using an independent state store which both SSR and CSR contexts have access to is a more reliable approach. This could be using a commercial state store like Redis or Memcached, or even a just a small standalone express server application that can be used as the state persistence application.
From here, we can define our mock handlers to read and write data from and to state:
import { graphql } from 'msw'; // assume for now that this interfaces with a separate state server application import { stateManagement } from './state-management'; const handlers = [ // `AddToCart` writes the updated cart to state... graphql.mutation('AddToCart', (req, res, ctx) => { const cart = stateManagement.getCart(req.variables.cartId); cart.items.push(req.variables.product) stateManagement.persistCart(cart); return res( ctx.data({ didAddToCart: true }) ); }), // ...so that the `Cart` query can read the current state of the cart graphql.query('Cart', (req, res, ctx) => { const cart = stateManagement.getCart(req.variables.id); if (!cart) { return res(ctx.errors([new GraphQLError('unknown cart')])); } return res(ctx.data({ cart })) }), ]
Writing stateful mocks has a number of additional benefits, which we won’t cover in detail here, but which give you an idea of the potential:
- You can “seed” that state server with data to reflect a starting point state for your tests. For example, test scenarios over the cart UI could have the state of the cart (i.e., the products it contains) seeded in the state server rather than having to call preceding mutation operations to set up that scenario.
- When developing your application, you can run against mocks instead of the real backend systems as part of your development flow. This means:
- Being able to write code without an active network connection, since none of your GraphQL requests actually rely on reaching a real server.
- Being able to write front-end features ahead of the required back-end capabilities having been developed and deployed.
What did this achieve for Formidable?
At Formidable, we used Mock Service Worker and the patterns described above during our development of a large, global e-commerce platform.
Our motivation for exploring and implementing GraphQL mocks was born out of having regular failing test runs due to volatile, unpredictable and unreliable upstream data and systems. Our rate of merging PRs was low because our failing tests were blocking our PRs and ofter required corrective work being done to the tests or upstream data and systems rather than the blockage being related to errors or regressions in the code written in the PR.
It addressed our high failure rate
Our failure rate was regularly in the 80%+ range:
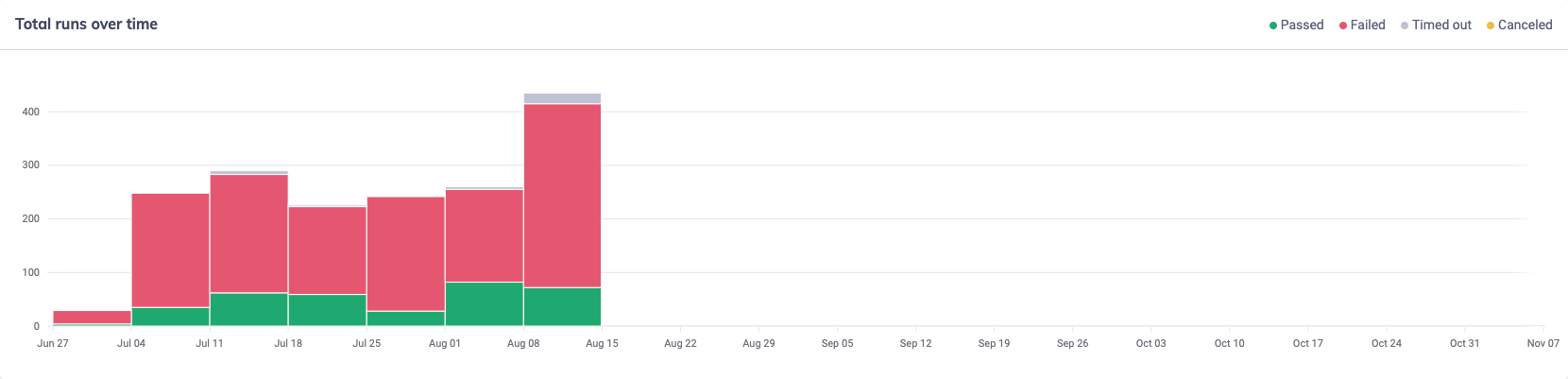
After the introduction of mocks for some of our GraphQL operations, we started to see incremental improvement in our pass rate. By mid-September 2022, around half of our GraphQL operations were mocked and we started to see the failure fate drop to 40%-60%, where the majority of failures were related to the remaining operations not yet mocked:
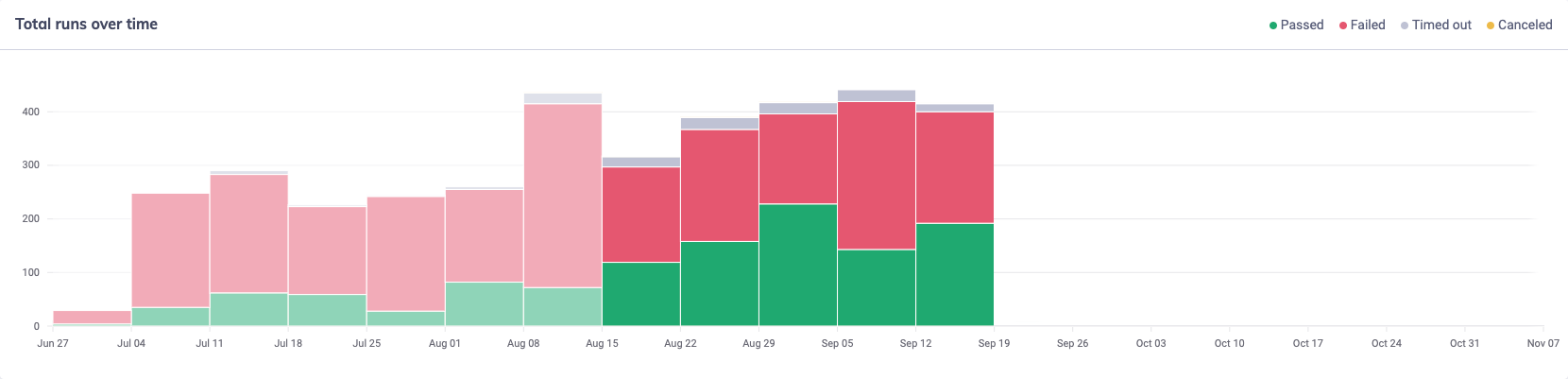
By the time all of our GraphQL operations (or at least those exercised by tests) were mocked, our failure rate had dropped to around 16%-25%, and upon reviewing these failures we found that they were almost exclusively genuine regressions which our tests had correctly flagged as failing.
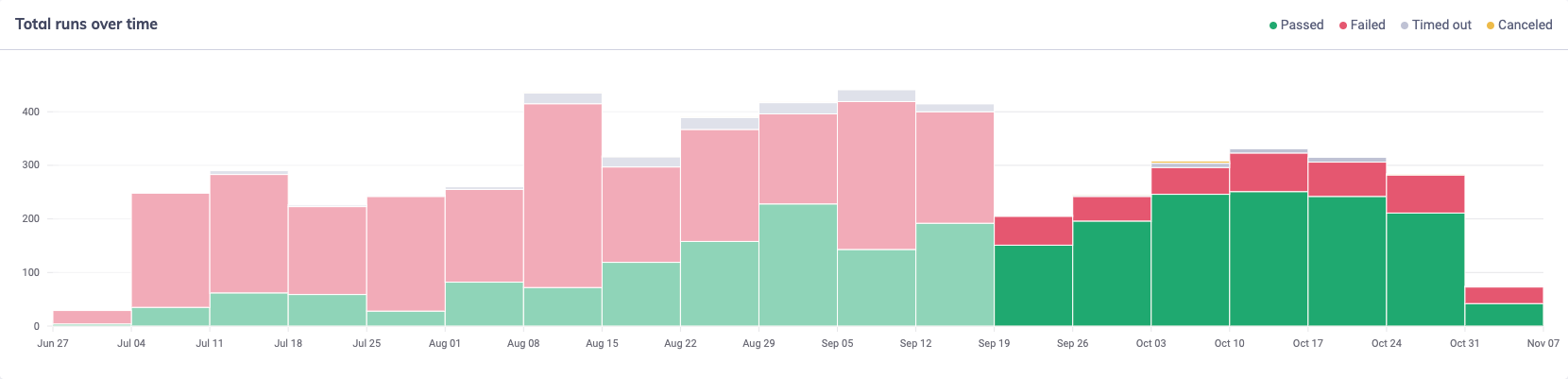
Finally, our tests could be relied upon to show us regressions and errors in our application, rather than becoming a nuisance and a noise that people had become accustomed to ignoring or attributing to false failures caused by other systems.
It allowed us to write more tests
When hooked up to real systems, we were limited in the type of test scenarios that we could write, given that the data was uncontrolled and often difficult-to-impossible to stage in a way which would allow certain scenarios to be tested.
Once we introduced mocks and therefore had total control over the data scenarios, we were able to write more exhaustive test suites which would cover scenarios previously either not reliable or not possible:
- Tests over data in transient or time-sensitive states, such as products being sold out or being on sale.
- Tests over sad-paths, such a cart being unavailable or a purchase transaction being rejected with a specific rejection reason, that we were not able to set up the data for.
With these new capabilities, the number of test suites we had in our codebase rose from 33 to 57 in the period shown in the charts above. The number of individual tests had risen from 409 to 551. Both of these figures reflect tests for existing features rather than newly added features, demonstrating our ability to write more exhaustive test suites for our application.
It made our tests faster to run
One of the benefits of mocks not touched upon yet is that we are not at the mercy of external system request latency, and so the speed of our “network requests” was almost instantaneous.
Our average run duration for our tests went from 🐌 10 minutes 33 seconds to ⚡ 3 minutes 21 seconds over the period displayed in the charts above, and this also takes into consideration the increased number of tests which were being run.
Parting thoughts
Mocking is not a new concept, however mocking GraphQL systems has been a less established space. Mock Service Worker as a tool released v1.0 in January 2023, and so this is still an emerging framework, but seems to have established itself as a great option for mocking GraphQL servers, and I would highly recommend it as a tool for mocking both GraphQL and REST backends.
Further reading
You can refer to the following resources for more information on GraphQL and mocking using msw:
- GraphQL specification: https://graphql.org/
- Mock Service Worker website: https://mswjs.io/
Related Posts
Mock factories make better tests

Lightweight Client-Side Tests with React-Testing-Library
 Emma Brillhart
Emma Brillhart